Welcome to UCR NLP Lab!
Lab Members
Director
Yue Dong, assistant professor of computer science and engineering
PhD Students
- Yu Fu, since Fall 2023
- 2023:EMNLP 2023 Findings
- 2024: AAAI 2024, NNACL 2024 TrustNLP workshop, ACL 2024, Microsoft 24 Summer Intern
- 2025: PAKDD 2025, ICLR 2025, AAAI 2025, Amazon 25 Summer Intern
- Erfan Shayegani (co-advise with Prof. Nael B. Abu-Ghazaleh), since Summer 2023
- 2024: ICLR2024, EMNLP 2024 Findings, Microsoft 24 Summer Intern
- 2025: ICML2025, Microsoft 25 Summer Intern
- Haz Sameen Shahgir, since Fall 2024
- 2024: ACL 2024 Findings, COLM 2024
- 2025: AAAI 2025, WSDM 2025, Amazon 25 Summer Intern
MSc Students
- Niyathi Allu
- Priyanshu Sharma
Research
The primary research objective of the UCR NLP lab is to create trustworthy, controllable, and safe natural language processing tools that can understand, reason, and produce human-like texts. The trustworthiness encompasses multiple facets, including producing useful but harmless content (AI safety), being detectable for responsible use (AI detection), being fair towards different social groups (AI fairness), and being factual with respect to context and world knowledge (hallucination reduction).
To meet this objective, we are committed to interdisciplinary research, incorporating methods and tools from natural language processing, machine learning, reinforcement learning, explainable AI, cybersecurity, optimization, and computer vision. Following are some selected research areas we focus on.
1. Trustworthy NLP - Hallucination Reduction
Our research focuses on hallucination reduction techniques for conditional text generation. Additionally, we aim to gain insight into why models hallucinate and how facts are processed in deep neural networks.
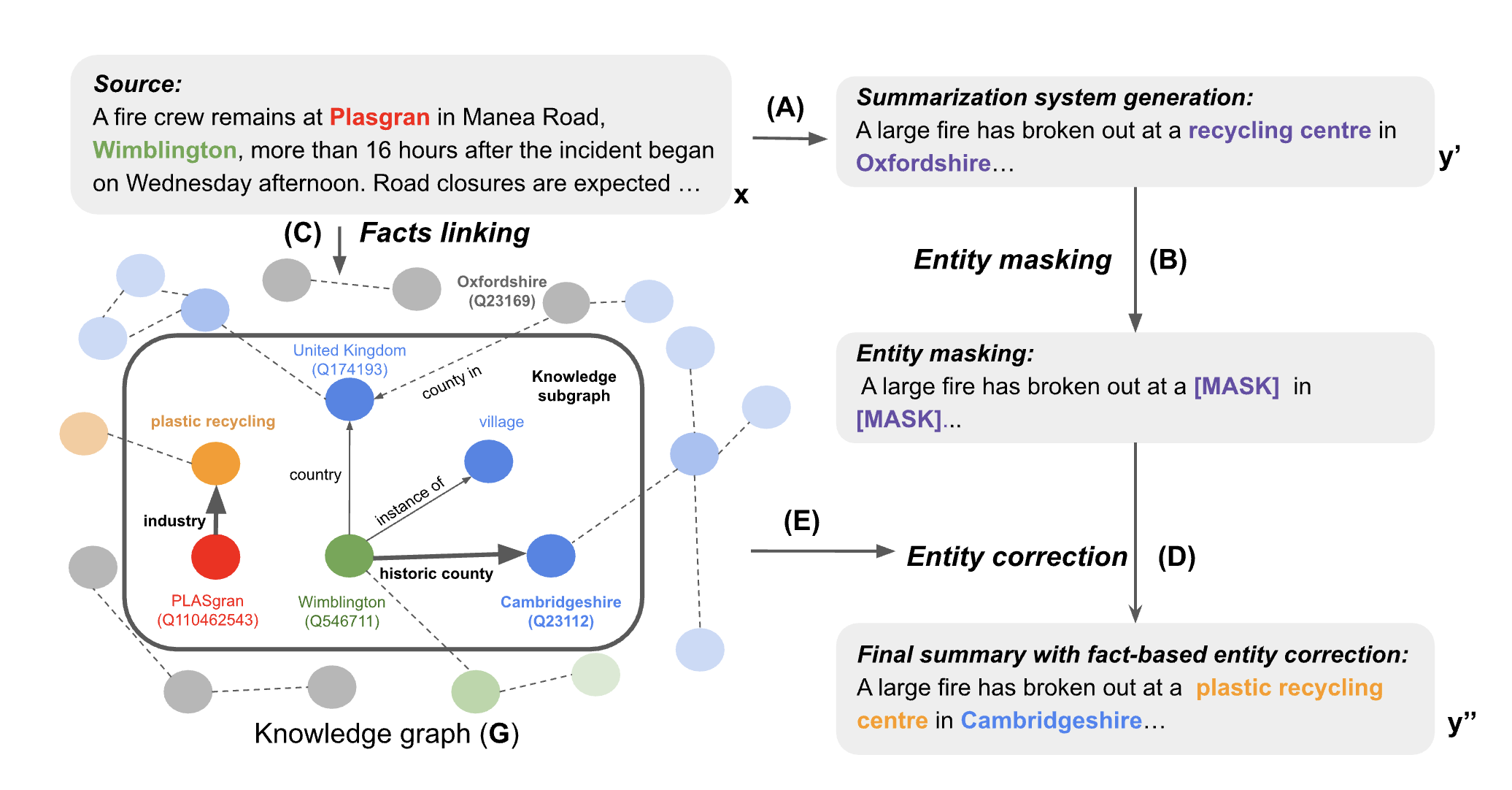
Previously Proposed methods include (i) using weakly supervised learning for fact error correction, as cited in [1], question-answering systems [2], and knowledge graphs [3]; and (ii) innovative learning [4] and detection approaches [5] for factual generation. These approaches have led to significant improvements in hallucination reduction, as measured by faithfulness metrics and human evaluations.
Related paper:
- [1] Factual Error Correction for Abstractive Summarization Models. Cao, M., Dong, Y., Wu, J., & Cheung, J. EMNLP 2020
- [2] Multi-Fact Correction in Abstractive Text Summarization. Dong, Y., Wang, S., Gan, Z., Cheng, Y., Cheung, J. , & Liu, J. EMNLP 2020
- [3] Faithful to the Document or to the World? Mitigating Hallucinations via Entity-Linked Knowledge in Abstractive Summarization. Dong, Y., Wieting, J., Verga, P. Findings of EMNLP 2022
- [4] Learning with Rejection for Abstractive Text Summarization. Cao, M., Dong, Y., He, J., & Cheung, J. EMNLP 2022
- [5] Hallucinated but Factual! Inspecting the Factuality of Hallucinations in Abstractive Summarization. Cao, M., Dong, Y., & Cheung, J. ACL 2022
2. AI Safety
Large Language Models (LLMs) Vulnerability: Large language models are demonstrating cutting-edge performance across a diverse range of application domains. However, the widespread implementation of these models (e.g., GPT-4) into autonomous systems is hindered by their vulnerability to adversarial attacks in the field of machine learning. Adversaries can introduce subtle alterations into input data, causing the model to make erroneous classifications or harmful generations.
Adversarial attacks: One emerging trend in generative AI involves integrating various types of data—such as images and audio—into into text-based LLMs. However, the inclusion of additional modality introduces underexplored vulnerabilities: it allows adversaries to exploit the system even with black-box access of LLMs. As detailed in our paper (https://arxiv.org/abs/2307.14539), this vulnerability presents significant security risks for a wide range of applications that depend on multi-modal models.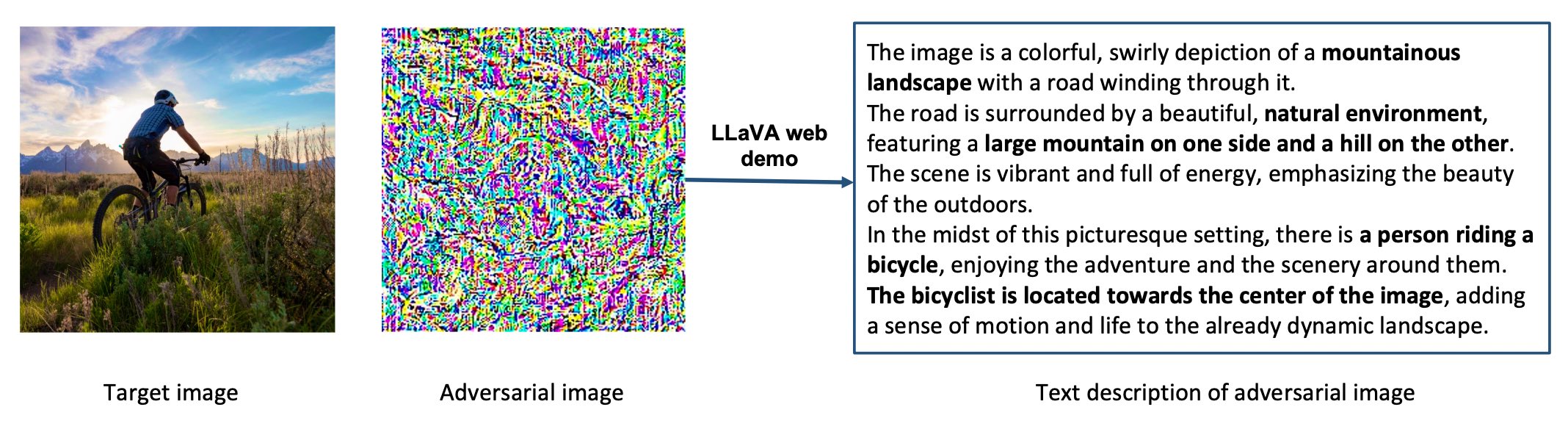
Hidden adversarial attacks: Additionally, humans have the ability to identify and fix problematic adversarial text attacks. However, our plug-and-play adversarial attack embeds these prompts within seemingly harmless images. This makes the attack difficult to patch and highly adaptable across systems. As a result, these concealed prompts can guide language models to act maliciously in systems that handle both text and images.

Related paper:
- NLP Tutorial: Vulnerabilities of Large Language Models to Adversarial Attacks
- Plug and Pray: Exploiting off-the-shelf components of Multi-Modal Models. Shayegani, E., Dong, Y., Abu-Ghazaleh, N. arXiv preprint
3. AI Detection
The increasing prevalence of new iterations of generative AI models has also raised concerns about the potential malicious use of human-like outputs. One solution to such concerns is to add watermarks to texts generated by AI, enabling AI generation detection. By aiming to develop robust methods for AI generation detection, we can mitigate risks and better understand how to integrate AI into society responsibly.
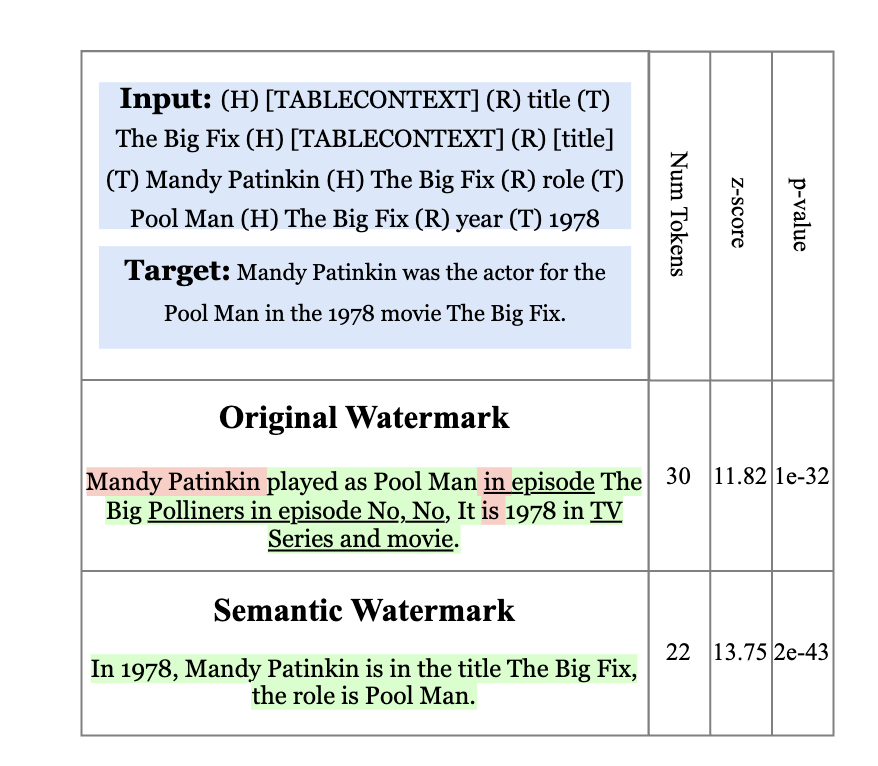
Watermark for conditional text generation: Our previous work shows that watermarking algorithms designed for LMs cannot be seamlessly applied to conditional text generation (CTG) tasks without a notable decline in downstream task performance. To address this issue, we introduce a simple yet effective semantic-aware watermarking algorithm that considers the characteristics of conditional text generation with the input context. Compared to the baseline watermarks, our proposed watermark yields significant improvements in both automatic and human evaluations across various text generation models, including BART and Flan-T5, for CTG tasks such as summarization and data-to-text generation. Meanwhile, it maintains detection ability with higher z-scores but lower AUC scores, suggesting the presence of a detection paradox that poses additional challenges for watermarking CTG.
Related paper:
- Watermarking Conditional Text Generation for AI Detection: Unveiling Challenges and a Semantic-Aware Watermark Remedy. Fu, Y., Xiong, D., Dong, Y. arXiv preprint
Yue Dong
Assistant Professor
Yue Dong is an assistant professor of computer science and engineering at the University of California Riverside. Her research interests include natural language processing, machine learning, and artificial intelligence. She leads the Natural Language Processing group, which develops natural language understanding and generation systems that are controllable, trustworthy, and efficient.